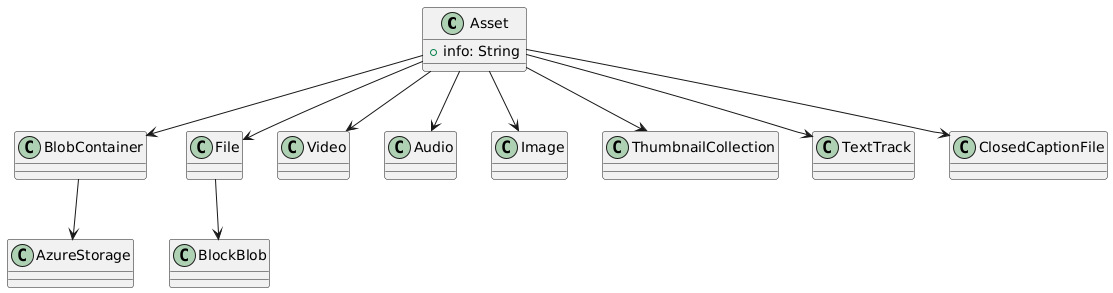
At Microsoft, documentation is created in Markdown, lives in GitHub repos, which you then fork and clone and do all the GitHub things and stuff. The markdown then gets transformed into HTML. (This is a really simplified explanation. The actual process is a lot more complicated.)
This script opens local Markdown files and summarizes them using Azure Cognitive Services TextAnalytics Extractive Summary. It’s available in version 5.3.0b2. It’s not available in the current verion, 5.2.1.
It doesn’t as yet write anything to the Markdown files or create a CSV file. All it does is return the summary to the terminal. I’m planning to use similar scripts to analyze what is in my content set so I can eventually use structured documentation methods to overhaul it. First, though I need to know what is there, and how it all maps to other content.
It does return an unclosed connection error, and fixing that it is on my TO DO list.
import asyncio
from dotenv import load_dotenv
# Get environment variables
load_dotenv()
import os
from azure.core.credentials import AzureKeyCredential
from azure.ai.textanalytics.aio import TextAnalyticsClient
endpoint = os.environ["AZURE_LANGUAGE_ENDPOINT"]
key = os.environ["AZURE_LANGUAGE_KEY"]
text_analytics_client = TextAnalyticsClient(
endpoint=endpoint,
credential=AzureKeyCredential(key),
)
async def get_summary(content,filename):
print(f"Summarizing {filename}")
#print(content)
document = [content]
poller = await text_analytics_client.begin_extract_summary(document)
extract_summary_results = await poller.result()
async for result in extract_summary_results:
if result.kind == "ExtractiveSummarization":
print("Summary extracted: \n{}".format(
" ".join([sentence.text for sentence in result.sentences]))
)
elif result.is_error is True:
print("...Is an error with code '{}' and message '{}'".format(
result.error.code, result.error.message
))
async def sample_extractive_summarization_async():
document = []
direct = "C:/absolute/path/to/markdown/files/"
for filename in os.listdir(direct):
#Open the file
file = open(direct + filename, "r")
#Read the contents of the file
content = file.read()
await get_summary(content,filename)
async def main():
await sample_extractive_summarization_async()
# TO DO: Fix unclosed connector error
if __name__ == '__main__':
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
asyncio.run(main())PS. For organizations that use an actual Component Content Management System (CCMS) to write and publish technical documentation and learning content, there may be a function in the system that automatically creates summaries of aggregated content. Paligo integrates with GitHub repos, although I haven’t seen it in action yet.
![PlantUML Syntax:</p>
<p>@startuml<br />
class AccountFilter {<br />
+ properties: MediaFilterProperties<br />
+ systemData: systemData<br />
}</p>
<p>class MediaFilterProperties {<br />
+ presentationTimeRange: PresentationTimeRange<br />
+ firstQuality: FirstQuality<br />
+ tracks: FilterTrackSelection[]<br />
}</p>
<p>class PresentationTimeRange {<br />
+ startTimestamp: integer<br />
+ endTimestamp: integer<br />
+ presentationWindowDuration: integer<br />
+ liveBackoffDuration: integer<br />
+ timescale: integer<br />
+ forceEndTimestamp: boolean<br />
}</p>
<p>class FirstQuality {<br />
+ bitrate: integer<br />
}</p>
<p>class FilterTrackSelection {<br />
+ trackSelections: FilterTrackPropertyCondition[]<br />
}</p>
<p>class FilterTrackPropertyCondition {<br />
+ property: string<br />
+ value: string<br />
+ operation: string<br />
}</p>
<p>AccountFilter –> MediaFilterProperties<br />
MediaFilterProperties –> PresentationTimeRange<br />
MediaFilterProperties –> FirstQuality<br />
MediaFilterProperties –> FilterTrackSelection<br />
FilterTrackSelection –> FilterTrackPropertyCondition<br />
@enduml</p>
<p>](http://www.plantuml.com/plantuml/img/VLD1JiCm4Bpx5RwZVY07LA3qXjH29Gw8mzRPH2iSEx8tHH7gtx5359p6xSqxEnwlnsEnzWoEkqOBfS5x-Q2KxGnlIJCw-IFkPEjiYuu9VI5Vi2Juw-qcE71yxncR3J0KoLgSHz7ijb4SFHe69ciErE0hc1eBkSl1WLwHyxplG1FtXTmcLMYo0_Nb8nmFEiJg3JMgAFBnEGsJrHw66Qo8K5WqRI79CDReGWTDcSNJyT_9bFPxqxcXIbcQJlWOfh5LbMjpL5QWCGKhwnG-puuzMgiHp7IHzFh3_4SA5d0YyyzSEZBiu1aqzsvygVx9cf8kFBn5IqCJ7icp8rC7w0IwmwIEXD6B4JkBUVfMg_ihYSi7AlBpoRdEdsNe5ctfeCZQUi5Us2FM8Kpnl_q2)